스프링 부트 배치 #3
스프링 부트 배치 #3
Chunk-Oriented-Processing
트랜잭션 경계 내에서 청크 단위로 데이터를 읽고 생성하는 기법.
읽은 데이터 수 == 청크 단위 수 => 쓰기 수행 및 트랜잭션 커밋
Spring Batch는 가장 일반적인 구현 내에서
Chunk Oriented Processing스타일을 사용
대량의 데이터에 대해 배치 로직이 실행된다고 했을 때, 청크 단위로 나누지 않고 실행하면 1개만 실패해도 나머지 처리건이 롤백되는데,
이를 청크 단위로 나눠서 처리하면, 실패한 배치 처리건이 존재해도 나머지 청크에 영향을 주지 않음하나의 Step에서 ItemReader -> ItemProcessor -> ItemWriter의 순서대로 처리하는 방식도 존재하지만,
스프링 배치에서는
TaskletStep처리 시나리오도 제공하고 있다.*
Tasklet
Chunk Oriented Processing전체 로직을 다루는 것을Tasklet이라 생각하면 쉽다.Tasklet은RepeatStatus.FINISHED를 반환하거나 예외를 throw 할 때까지TaskletStep에 의해 반복적으로 호출Tasklet인터페이스는execute매소드 하나만 존재하며 작업 끝나면RepeatStatus.FINISHED를 반환하며, 작업이 계속되면RepeatStatus.CONTINUABLE을 반환한다.1
2
3
4public interface Tasklet {
RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception;
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
public class InactiveItemTasklet implements Tasklet {
private UserRepository userRepository;
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
Date date = (Date) chunkContext.getStepContext().getJobParameters().get("nowDate");
LocalDateTime now = LocalDateTime.ofInstant(date.toInstant(), ZoneId.systemDefault());
List<User> inactiveUsers = userRepository.findByUpdatedDateBeforeAndStatusEquals(
now.minusYears(1), UserStatus.ACTIVE
).stream().map(User::setInactive).collect(Collectors.toList());
userRepository.saveAll(inactiveUsers);
return RepeatStatus.FINISHED;
}
}- 파일 처리 Tasklet 예제
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
public Job taskletJob() {
return this.jobBuilderFactory.get("taskletJob")
.start(deleteFilesInDir())
.build();
}
public Step deleteFilesInDir() {
return this.stepBuilderFactory.get("deleteFilesInDir")
.tasklet(fileDeletingTasklet())
.build();
}
public FileDeletingTasklet fileDeletingTasklet() {
FileDeletingTasklet tasklet = new FileDeletingTasklet();
tasklet.setDirectoryResource(new FileSystemResource("target/test-outputs/test-dir"));
return tasklet;
}
Listner
- 배치 처리 흐름에서 전후처리에 해당하는 구간에 Listener를 설정 할 수 있다.
- Job의 전후, Step의 전후, 각 청크 단위에서의 전후 등 세세한 과정 실행 시 특정 로직을 할당 할 수 있다.
- 인터페이스 구현하는 방법과 어노테이션을 할당하여 구현하는 방법이 있다.
| 인터페이스 | 어노테이션 | 설명 |
|---|---|---|
| JobExecutionListener | @BeforeJob, @AfterJob |
Job 실행 전후 처리 |
| ChunkListener | @BeforeChunk,@AfterChunk, @AfterChunkError |
Chunk 실행 전후, 에러 처리 |
| ItemReadListener | @BeforeRead, @AfterRead, @OnReadError |
Read 실행 전후, 에러 처리 |
| ItemProcessListener | @BeforeProcess, @AfterProcess, @OnProcessError |
Process 실행 전후, 에러 처리 |
| ItemWriteListener | @BeforeWrite, @AfterWrite, @OnWriteError |
Write 실행 전후, 에러 처리 |
| StepExecutionListener | @BeforeStep, @AfterStep |
Step 실행 전후 처리 |
| SkipListener | @OnSkipInRead, @OnSkipInWrite, @OnSkipInProcess |
Skip 발생 시 처리 |
1 | // 1. Interace 구현 |
Flow, 흐름제어
Job 실행에서 Step의 실패가 반드시 Job이 실패해야 한다는 것을 의미하지 않는다. 또한, 다음 Step에서 어떤 단계가 실행되어야 하는지를 흐름 제어가 필요한 상황도 충분히 생길 수 있다. 스프링 배치에서는 이러한 순차 처리 케이스와 조건 처리 케이스에 대해 구현체를 제공하고 있다.
Sequential Flow
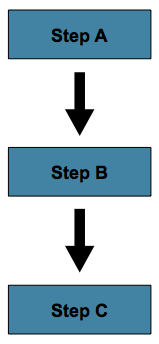
Step들을 처리하는 가장 일반적인 시나리오로 모든Step들이 연속적으로 실행되는 Flow.- 다시 말해,
Step A가 완벽하게 수행되면Step B가 실행되고 그 이후에Step C까지 실행되는 구조이다. 만약Step A가 실패하게 될 경우 이후Step들은 실행되지 않으므로 해당Job은 실패하게 된다. 위와 같은 플로우를 실행하는Job은 아래와 같이 생성하면 된다.1
2
3
4
5
6
7
8
public Job job() {
return this.jobBuilderFactory.get("job")
.start(stepA())
.next(stepB())
.next(stepC())
.build();
}
Conditional Flow
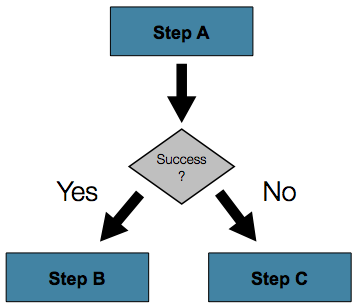
- 대부분의 경우, Sequential Flow를 통하여 해결이 되겠지만, 흐름 제어가 필요한 상황이 있을 수 있다. 예를 들어,
Step A의 성공 유무를 체크하여 분기가 필요하다면 아래 코드이Job설정이 가능하다.1
2
3
4
5
6
7
8
9
public Job job() {
return this.jobBuilderFactory.get("job")
.start(stepA())
.on("*").to(stepB())
.from(stepA()).on("FAILED").to(stepC())
.end()
.build();
} on메소드는 간단한 패턴 일치를 사용하여 Step의 실행결과ExitStatus를 일치시킴*은 0 개 이상의 문자와 일치.?은 정확히 한 문자 일치예를 들어, “c*t”은 “cat” 및 “count”에 매칭 될 수 있다. 반면에, “c?t”은 “cat”에 매칭될 수 있지만, “count”에는 매칭 될 수 없다.
ExitStatus와BatchStatus의 값을 구분하는 것이 중요ExitStatus
1
.from(stepA()).on("FAILED").to(stepB())
위와 같은 Job코드가 있다고 가정할 때, 여기에서 표현하는 상태 값은
Step에서의 ExitStatus의 FAILED 상태 값을 나타낸다. 다시 말해,Step의 처리 상태를 표현하며, 상태값은UNKNOWN,EXECUTING,COMPLETED,NOOP,FAILED,STOPPED이 존재한다.BatchStatus
JobExecution와StepExecution양쪽에서 사용하는 열거형 값으로 프레임워크에서Job과Step의 상태를 기록하는 용도로 사용한다. 상태 값으로는 COMPLETED, STARTING, STARTED, STOPPING, STOPPED, FAILED, ABANDONED, or UNKNOWN이 존재한다.
- 만약, ExitStatus의 값이 FAILED라고 하면, Job의 BatchStatus값 역시 FAILED로 처리된다. 이밖의 경우는 BatchStatus와 ExitStatus 모두 COMPLETE 상태로 처리된다.